离线/实时数据同步打通数据汇聚共享任督二脉 |
您所在的位置:网站首页 › 在线数据 离线数据 › 离线/实时数据同步打通数据汇聚共享任督二脉 |
离线/实时数据同步打通数据汇聚共享任督二脉
|
在业务分析过程中,随着应用需求场景增多,企业需要依据自身业务场景判断选择实时数据还是离线数据。那么,实时数据与离线数据到底有什么不同?他们各自的优势又是什么呢?企业应该怎样选择实时数据或是离线数据驱动业务发展,更好地迈向数字化时代呢? 针对这一问题,科杰科技将离线数据同步与实时数据同步进行解读分析,帮助企业更好地理解离线数据同步与实时数据同步优点及其应用情况。 离线数据同步 数据通道为数据平台提供丰富的结构化、半结构化、非结构化数据源之间高速稳定的数据离线同步能力,为业务数据进出平台数据仓库、数据集市提供完整的解决方案,提供丰富多样、简单易用的数据处理功能,为后续的查询、分发、计算和分析提供数据基础,包括数据源管理、数据导入、文件导入、HDFS文件导入、Flume文件采集;数据导出、DB导出、数据推送至集市等功能。
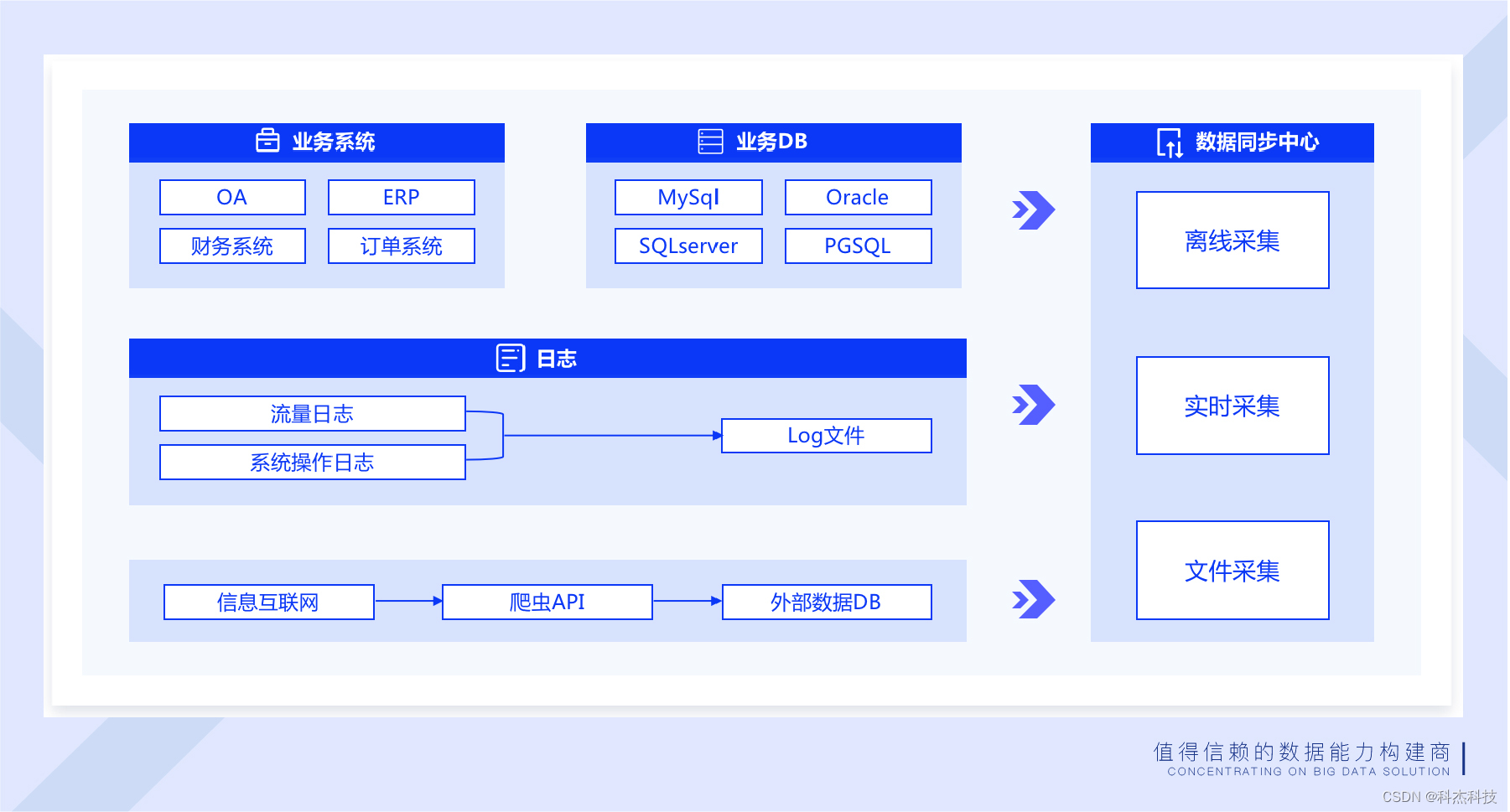
多源、异构数据的离线接入 离线数据同步融合关系型数据库、非关系型数据库、大数据平台、文件系统的离线数据接入能力,支持各类型数据源之间的数据交互,适用于企业内部各数据类型的导入与导出场景。
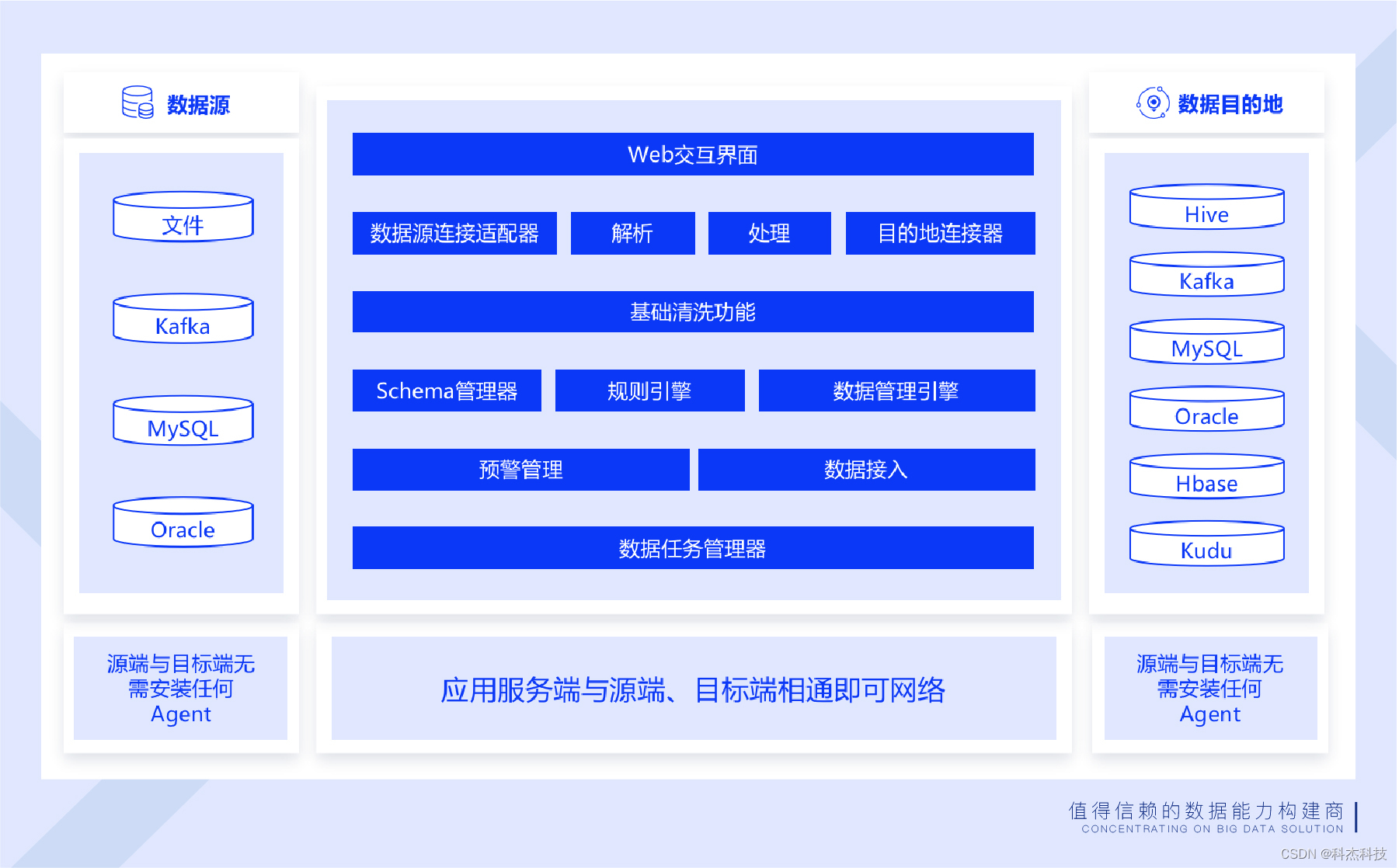
表同步与库同步 针对库表结构的数据提供两种接入模式,表同步与库同步。 表同步支持常规导入、动态表名导入、多表导入以及分库分表导入,能够支撑企业内部多种数据存储形式的数据接入场景;库同步支持整库同步和批量表同步,适用于多表导入的应用场景。 数据读取 系统提供各类型数据源的数据读取配置,针对关系型数据库和非关系型数据库可选择数据读取的字段,支持界面可视化设置数据转换函数,并支持增量读取数据;针对大数据平台和文件系统可选择数据读取区域,支持动态文件读取。 产品优势 支持库表到库表、库表到文件、文件到库表等多种数据接入场景,能够满足企业内部各种数据导入或导出需求; 提供任务异常处理机制,任务失败后可自动重启,支持断点续传、异常恢复,保证数据的完整性。 实时数据同步 Keen Dsync是数据中台实时数据同步交换中心,是一站式、智能化、多源数据同步产品,用于企业异构多源数据融合,解决企业内关系型数据库、非关系型数据库、大数据平台、文件系统等复杂异构数据源之间、大数据量高并发下的数据交互和数据同步问题,是企业实现数据统一共享和分发的利器。 多源、异构数据的实时同步 支持同构和异构数据源等任意数据源之间的数据交互和数据同步,支持关系型数据库、非关系型数据库、大数据平台、文件系统,可解决企业内部多源异构数据融合的复杂场景。 数据清洗 支持在数据同步前设置清洗规则,对无效、空值、重复数据、残缺数据、异常数据等脏数据进行清洗和转换,满足基本的数据清洗要求。 统一数据共享和分发 支持一对多数据共享和分发,不对源系统产生影响,支持多类型数据源集成,打破数据孤岛,实现数据统一管理。 实时数据同步产品架构图
产品能力 支持全量和增量同步 开启repeatable read事务保证数据可以读到。然后进行flush table with read lock 操作,添加一个读锁,防止这个时候有新的数据进入影响数据的读取,这时开始一个truncation with snapshot,我们可以记录当前binlog的offset 并标记一个snapshot start,这时的offset 为增量读取时开始的offset。当事务开始后可以进行全量数据的读取。record marker这时会将生成record 写到 kafka 中,然后commit 这个事务。当全量数据push完毕后解除读锁并且标记snapshot stop,此时全量数据已经都进入kafka了,之后从之前记录的offset开始增量数据的同步。 无Agent,不会对数据源端造成压力 业务上经常会存在大数据量多个任务同步,这时就很难平衡数据传输对源端的压力和目的端的实时性,Keen Dsync 做了大量相关测试来优化不同的连接池,支持整库同步、目的端字段建表、无主键同步、开放数据传输效率的自定义化,供客户针对自己的业务系统定制合适的传输任务,对于不同种类的数据库的传输进行优化和调整,保证数据传输的高效性。 故障自动恢复 任务recover时,获取目标文件在hdfs 上的租约,获取到租约后就可以开始读之前写入时候的log,如是第一次会创建一个新的log,并标记一个begin,记录当时的kafka offset。然后清理之前遗留下来的临时数据,清理掉之后再重新开始同步直到同步结束会标记一个end。如果没有结束的话就相当于正在进行中,正在进行中每次都会提交当前同步的offset,来保证出现意外后会回滚到之前offset。如果需要读写的HDFS当前文件是被占用的,需要等待直到可以获取到租约。 断点续传 数据同步分为全量同步和增量同步,全量同步实际是一个批处理。在批处理时,都是进行的处理all or nothing【要么全部同步成功,要么全部同步失败】,而实际应用中,大数据量同步一个批量会占用相当长的时间,时间越长可靠性就越难保障,往往会出现断掉的情况,断掉后需要重新处理会让很多人崩溃。keen Dsync【实时数据同步系统】通过管理数据传输时的position 来做到断点续传,即使一个大规模的数据任务发生了意外,可以继续从断掉的点来继续之前的任务,大大缩短了同步的时间,提高了同步的效率。 保障端到端数据的一致性 keen Dsync 是通过将同步数据写入到数据库之前先写临时文件,当一个批次结束后,再将这个临时文件重命名到正式文件【正式的文件名会包含kafka offset】,确保每次提交后的正式文件一致性,如果中途出现写入错误,会回滚一下当前任务,将临时文件删除重新写入。 灵活&易用性 1)可视化创建同步任务; 2)支持一个来源端多个目标端的任务同步和单独管理; 3)支持目标端自动建表; 4)支持整库同步、单表同步; 5)支持主键自动检测、目标端自定义主键、添加自定义列、描述; |
【本文地址】
今日新闻 |
推荐新闻 |